The final optimal state value function and deterministic policy obtained when using exploring starts monte carlo approximation.
Both plots are very close (but perhaps not identical) to the plots presented in the book in this section.
We first present the optimal state value function and then the optimal policy. The optimal state value function looks like
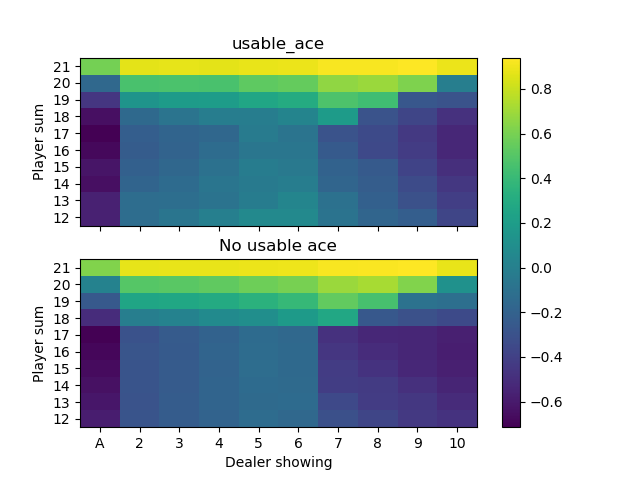
The optimal policies look like
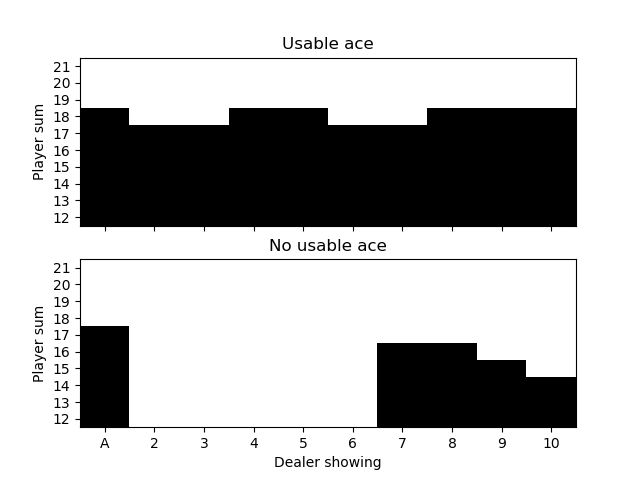
John Weatherwax